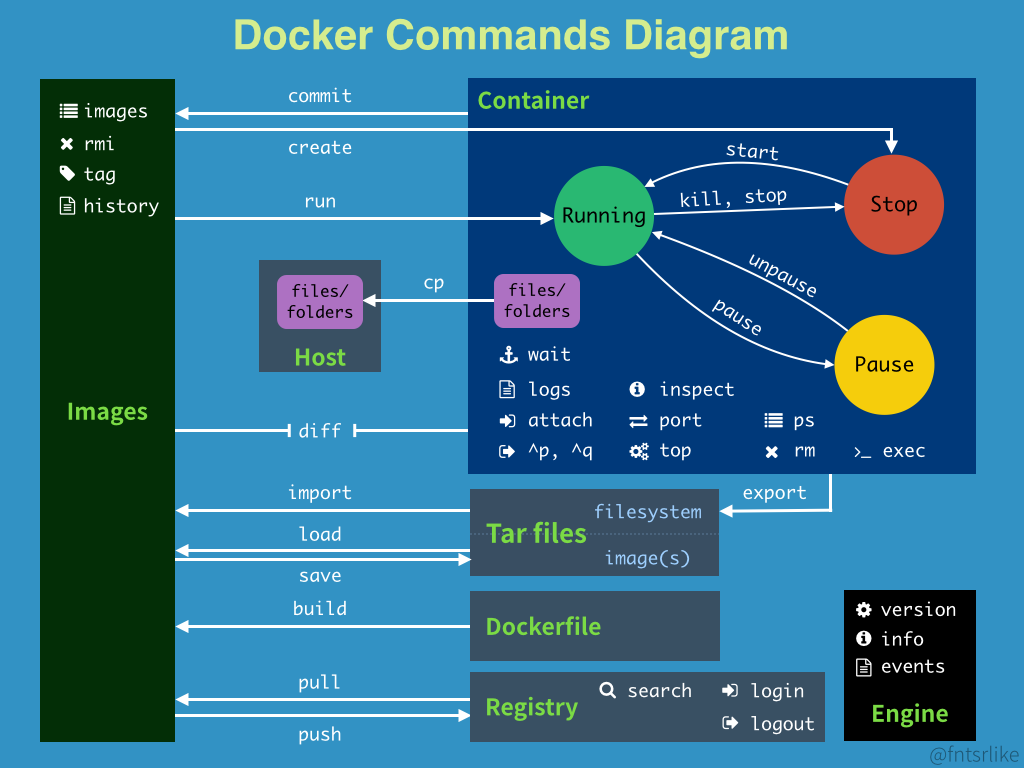
Docker 深入淺出系列第一篇,介紹 Docker 在 Windows 中的運作原理 (HyperV + Docker Daemon)、Image 與 Container 的關係、以及 Docker 操作流程圖解
Please disable your AD blocker to continue using this site. Ads help us keep the content free! please press keyboard F5 to refresh page after disabled AD blocker
請關閉廣告攔截器以繼續使用本網站。廣告有助於我們保證內容免費。謝謝! 關閉後請按 F5 刷新頁面
Docker 深入淺出系列第一篇,介紹 Docker 在 Windows 中的運作原理 (HyperV + Docker Daemon)、Image 與 Container 的關係、以及 Docker 操作流程圖解
使用 Docker 快速建立 MSSQL 資料庫環境,搭配 VSCode Extension 取代 SSMS 進行連線查詢,大幅減少安裝時間與磁碟空間,支援 Linux 環境
SQLQueryStress 資料庫壓測工具教學:在 Dev 環境模擬高併發查詢,找出 SQL Server 效能瓶頸與 Lock 問題的實戰案例
使用 Autofac Interceptor 實作 AOP Lock 架構:透過 LockAttribute 宣告式互斥鎖機制,解決多執行緒交易 DeadLock 問題
介紹 .NET 三種記憶體區塊:Heap、Stack、Global 的差異與用途,了解值類型與參考類型在不同記憶體區域的配置方式

淺談 SQL Server Lock 機制第一篇:從 ACID 交易特性延伸,了解 SQL Server 中 Shared Lock、Exclusive Lock、Update Lock 等鎖定類型與鎖定粒度
解決 SQL Server JOIN 範圍條件時索引效能問題:當執行計畫預估值不準確時,如何透過 Index 設計讓 JOIN 條件範圍查詢發揮最佳效能
SQL Server MERGE 語法使用 DECLARE 變數作為比對條件時的常見問題與解法,實現 UPSERT (存在就更新、不存在就新增) 的正確寫法
ACID 資料庫交易特性介紹:原子性、一致性、隔離性與持久性,以及 SQL Server 中 XACT_ABORT 對交易錯誤處理的影響
分析 C# 字串插值中隱藏的 Boxing 問題,比較字串插值直接傳入 int 與先呼叫 ToString() 的效能差異